
https://github.com/weaviate/Verba
Github项目详情见【阅读原文】
项目简介
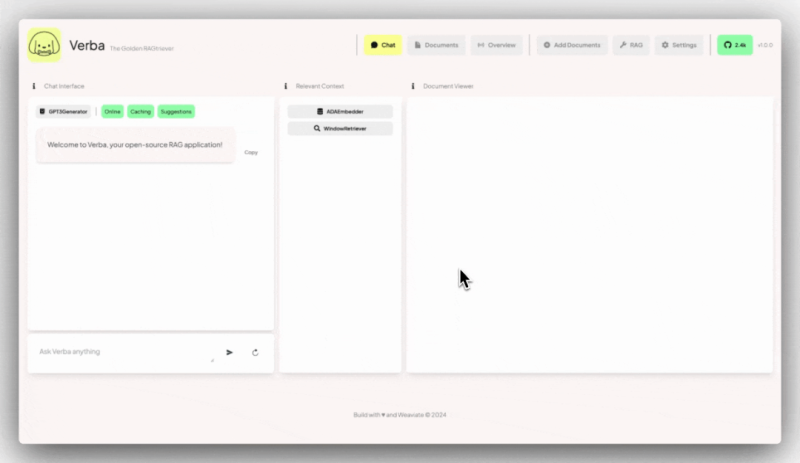
Verba 是一个开源应用程序,提供了一个端到端、流畅且用户友好的检索增强型生成(Retrieval-Augmented Generation, RAG)接口。
用户可以通过简单的几个步骤,探索数据集并轻松提取洞见,无论是本地使用 HuggingFace 和 Ollama,还是通过 OpenAI、Cohere 和 Google 等大型语言模型(LLM)提供商部署在云端。



使用场景
-
当地部署:用户可以本地部署 Verba,结合 HuggingFace 和 Ollama 使用。 -
云端部署:通过云服务提供商如 OpenAI、Cohere 和 Google 进行部署。 -
数据查询与交互:Verba 可以作为一个完全可定制的个人助理,用于查询和与数据交互,无论是本地还是通过云端部署。 -
解决文档相关问题:用户可以围绕文档提出问题,交叉引用多个数据点,或从现有知识库中获得观点。
使用方法
1. 安装 Verba
-
通过 pip 安装: pip install goldenverba -
从源代码构建:克隆仓库后使用 pip install -e .安装 -
使用 Docker 部署:克隆仓库并使用 docker compose up -d命令启动
2. 配置 API 密钥
创建 .env 文件并根据需要配置环境变量,如 Weaviate、Ollama、Google、Unstructured 和 OpenAI 的 API 密钥。
3. 访问 Verba
默认情况下,可以通过访问 localhost:8000 来使用 Verba 的前端界面。
4. 导入数据
使用 Verba 的“添加文档”页面来导入数据,支持多种数据类型和嵌入模型。
5. 查询数据
在数据导入后,可以使用“聊天”页面提出相关问题,并获得与问题语义相关的数据块和由选定模型生成的答案。
注:本文内容仅供参考,具体项目特性请参照官方 GitHub 页面的最新说明。
欢迎关注&点赞&在看,感谢阅读~
原文始发于微信公众号(AIGC创想者):Verba:3.1K+ Star!一个开源的RAG聊天机器人,提供了一个端到端、流程化且用户友好的界面
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
喜欢就支持一下吧





相关推荐
暂无评论内容