
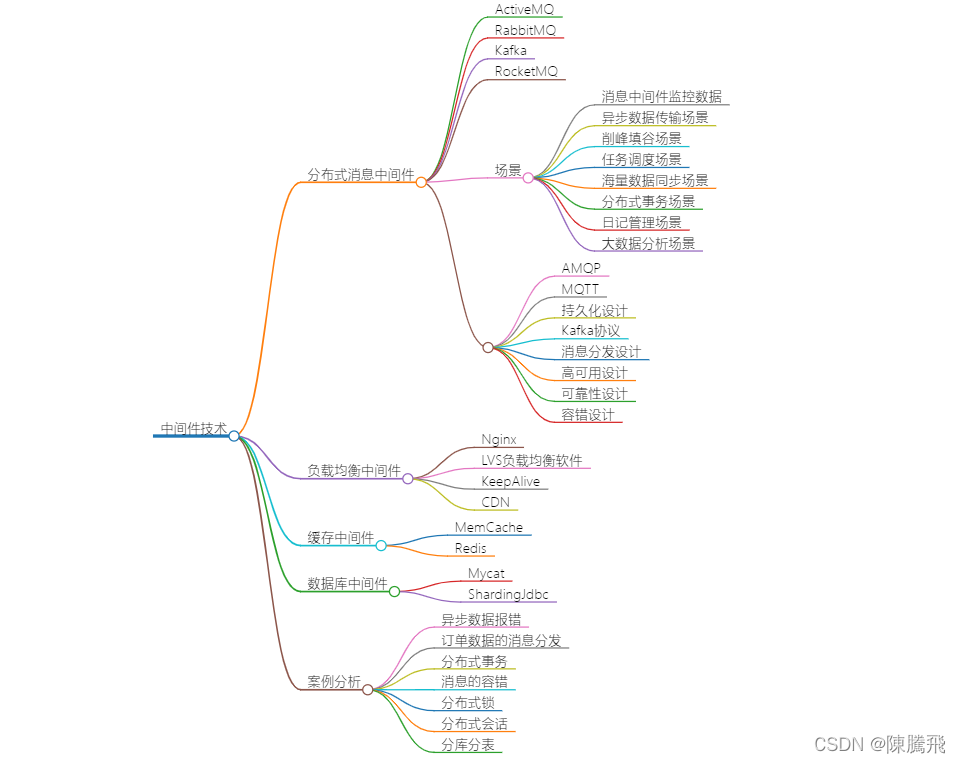
索引是什么?
索引的概念:索引是⼀种特殊的⽂件(InnoDB数据表上的索引是表空间的⼀个组成部分),它们包含
着对数据表⾥所有记录的引⽤指针。更通俗的说,数据库索引好⽐是⼀本书前⾯的⽬录,能
加快数据库的查询速度
索引的作用:索引的⽬的在于提⾼查询效率,使原始的随机全表扫描变成快速顺序锁定数据
索引高性能的保证:把查询过程中的随机事件变成顺序事件
数据保存在磁盘上,⽽为了提⾼性能,每次⼜可以把部分数据读⼊内存来计算,访问磁盘的
成本⼤概是访问内存的⼗万倍左右
磁盘的IO与预读:考虑到磁盘IO是⾮常⾼昂的操作,计算机操作系统做了⼀些优化,当⼀次
IO时,不光把当前磁盘地址的数据,⽽是把相邻的数据也都读取到内存缓冲区内,因为局部
预读性原理告诉我们,当计算机访问⼀个地址的数据的时候,与其相邻的数据也会很快被访
问到。每⼀次IO读取的数据我们称之为⼀⻚(page)。具体⼀⻚有多⼤数据跟操作系统有关,
⼀般为4k或8k
索引底层实现原理
索引的目的:提⾼查询效率,可以类⽐字典,如果要查“mysql” 这个单词,我们肯定需要定位到m
字⺟,然后从下往下找到y字⺟,再找到剩下的sql
索引的设计难度:
查询要求:等值查询,还有范围查询(>
、
<
、
between
、
in)
、模糊查询(like)
、并集查询
(or)
、
<
、
between
、
in)
、模糊查询(like)
、并集查询
(or)
数据量:超过⼀千万数据通过索引查询,查询性能保证
索引的数据结构
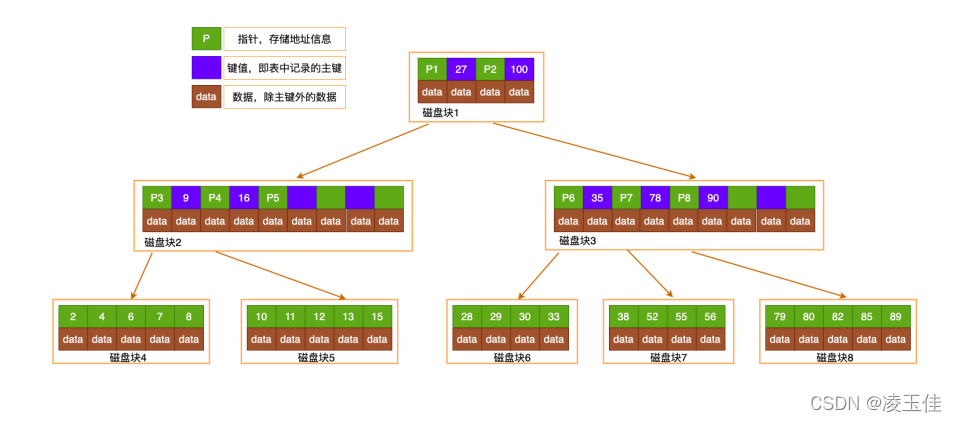
B-TREE结构:
每个节点都是⼀个⼆元数组
: [key, data]
,所有节点都
可以存储数据。
key
为索引
每个节点都是⼀个⼆元数组
: [key, data]
,所有节点都
可以存储数据。
key
为索引
key,data为除key之外的数据

B-Tree
的缺点:插⼊删除新的数据记录会破坏
B-Tree
的性质,因此在插⼊删除时,需要对树进⾏⼀
的缺点:插⼊删除新的数据记录会破坏
B-Tree
的性质,因此在插⼊删除时,需要对树进⾏⼀
个分裂、合并、转移等操作以保持B-Tree
性质。造成
IO
操作频繁。区间查找可能需要返回上
性质。造成
IO
操作频繁。区间查找可能需要返回上
层节点重复遍历,IO
操作繁琐
操作繁琐
B+Tree
的改进:⾮叶⼦节点不存储
data
,只存储索引
key
;只有叶⼦节点才存储data
的改进:⾮叶⼦节点不存储
data
,只存储索引
key
;只有叶⼦节点才存储data
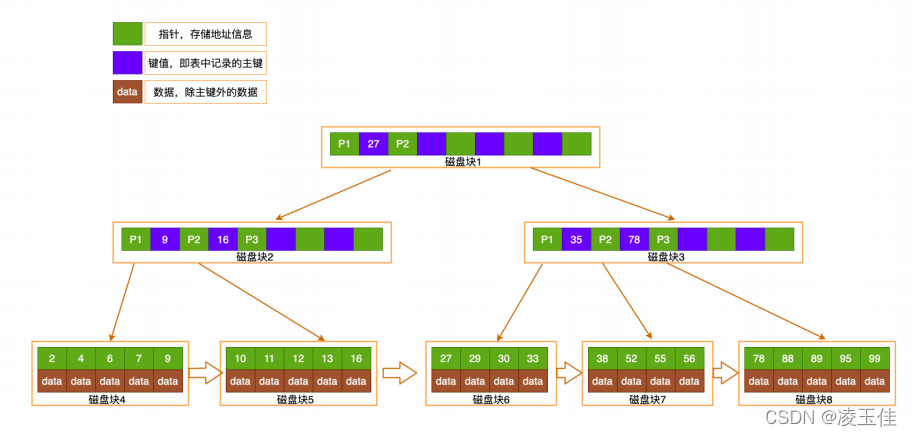
B+TREE高性能保证:3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,
性能提⾼将是巨⼤的,如果没有索引,每个数据 项都要发⽣⼀次IO,那么总共需要百万次的
IO,显然成本⾮常⾮常⾼
在B+Tree
的每个叶⼦节点增加⼀个指向相邻叶⼦节点的指针,就形成了带有顺序访问指针的
的每个叶⼦节点增加⼀个指向相邻叶⼦节点的指针,就形成了带有顺序访问指针的
B+Tree
B+TREE 只在叶⼦节点存储数据
&
所有叶⼦结点包含⼀个链指针 &
其他内层⾮叶⼦节点只存
&
所有叶⼦结点包含⼀个链指针 &
其他内层⾮叶⼦节点只存
储索引数据。只利⽤索引快速定位数据索引范围,先定位索引再通过索引⾼效快速定位数
据。
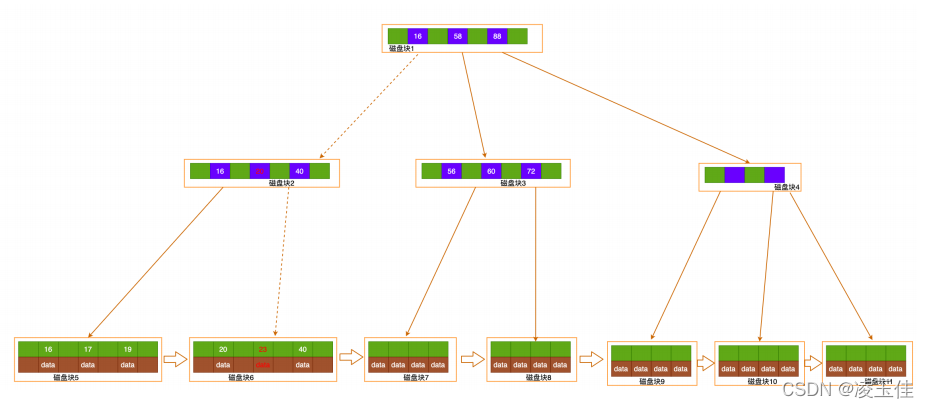
索引检索过程
索引值匹配检索过程:确定定位条件
,
找到根节点
Page No,
根节点读到内存,
逐层向下查找
,
读取叶
,
找到根节点
Page No,
根节点读到内存,
逐层向下查找
,
读取叶
⼦节点Page,
通过 ⼆分查找找到记录或未命中。(select * from user_info where id = 23
) 查
通过 ⼆分查找找到记录或未命中。(select * from user_info where id = 23
) 查
询类接⼝⼀般在30ms~50ms
插⼊、修改⼀般在
50ms~100ms
插⼊、修改⼀般在
50ms~100ms
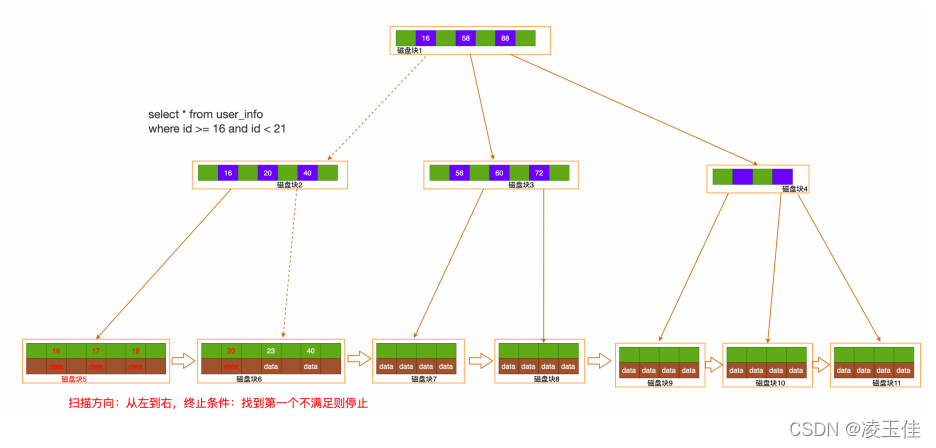
索引范围查找:读取根节点⾄内存
,
确定索引定位条件
id=18,
找到满⾜条件第⼀个叶节点, 顺序扫
,
确定索引定位条件
id=18,
找到满⾜条件第⼀个叶节点, 顺序扫
描所有结果,
直到终⽌条件满⾜
id >=21
(
select * from user_info where id >= 16 and id <
直到终⽌条件满⾜
id >=21
(
select * from user_info where id >= 16 and id <
21)
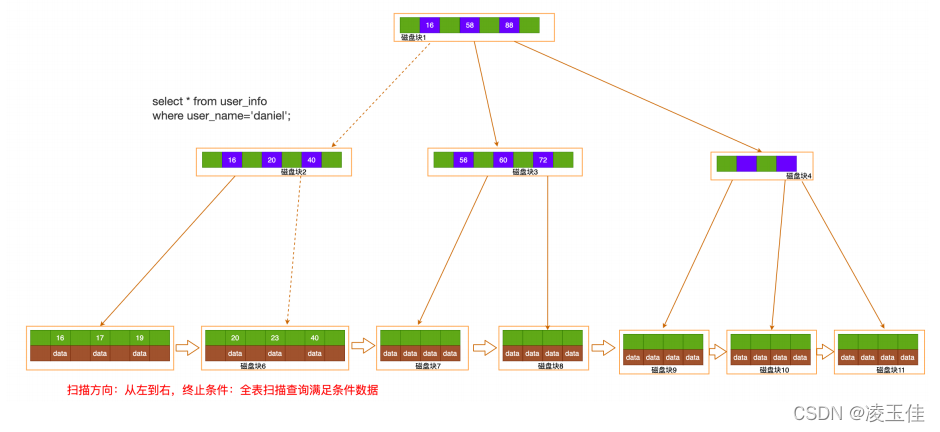
全表扫描:直接读取叶节点头结点, 顺序扫描, 返回符合条件记录, 到最终节点结束(select *
from user_info where user_name = ‘daniel’)
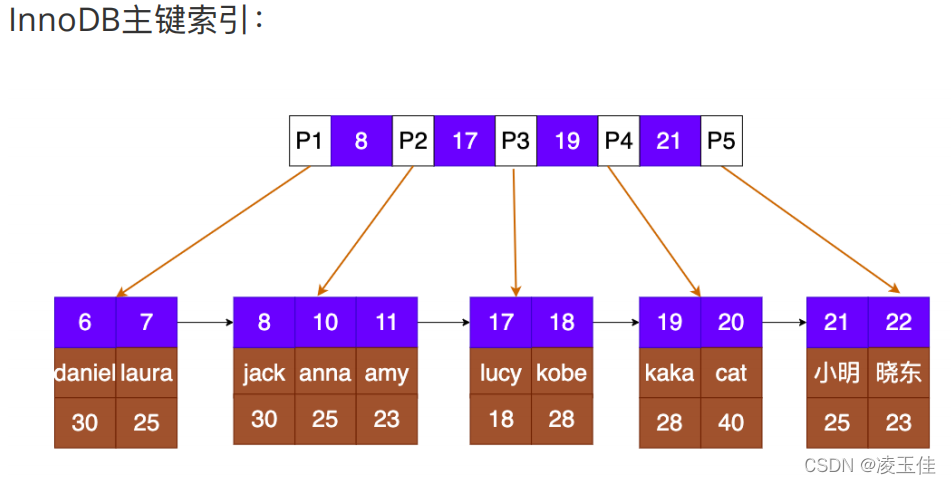
主键索引:是一种聚簇索引,数据和索引保存在一起 。通过索引可以直接找到数据,效率高
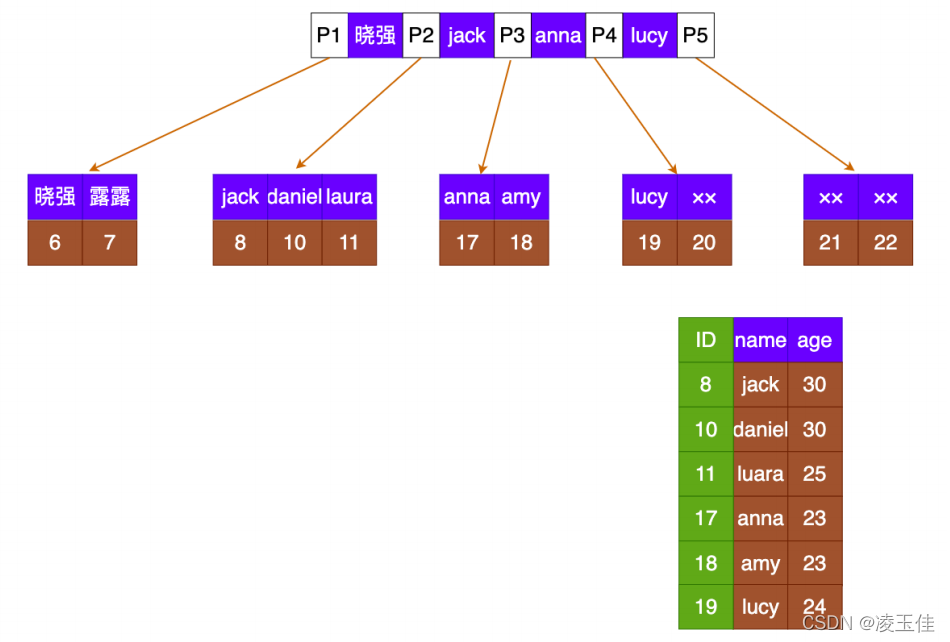
非主键索引:通过索引找到id,再根据id查询数据。
唯⼀索引和普通索引的区别
关于唯⼀索引
定义:
UNIQUE
索引可以强制执⾏值唯⼀的⼀列或多列。⼀个表可以有多个UNIQUE
索引。
UNIQUE
索引可以强制执⾏值唯⼀的⼀列或多列。⼀个表可以有多个UNIQUE
索引。
场景:联系⼈的电⼦邮件唯⼀、联系⼈的身份证唯⼀
123@q q.com
数据库层⾯的严格唯⼀
123@q q.com
数据库层⾯的严格唯⼀
唯⼀索引与普通索引的性能区别:
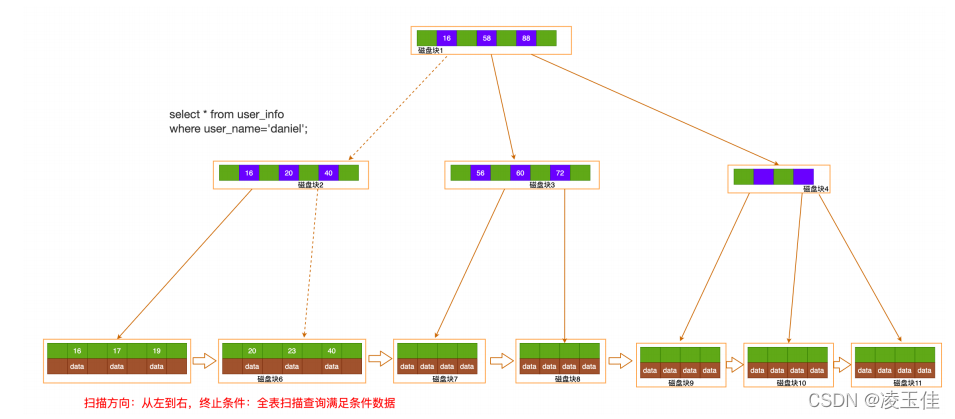
查询上的区别:对唯⼀索引,由于索引定义了唯⼀性,查找到第⼀个满⾜条件的记录后,就会停⽌
检索对普通索引,查找到满⾜条件的第⼀个记录’ab‘
后,需查找下个记录,直到碰到第⼀个不
后,需查找下个记录,直到碰到第⼀个不
满⾜k=’ab‘条件的记录结论:mysql
采⽤
page
⻚(⼀⻚
16K
)为数据单位从磁盘load出数据,
采⽤
page
⻚(⼀⻚
16K
)为数据单位从磁盘load出数据,
除⾮刚好值为’ab‘
的记录在⼀⻚的最后⼀条数据,否则执⾏性能区别微乎其微
的记录在⼀⻚的最后⼀条数据,否则执⾏性能区别微乎其微
change buffer
的定义:⼀种特殊的数据结构,该结构在 次要索引
中记录对
⻚
的更改
的定义:⼀种特殊的数据结构,该结构在 次要索引
中记录对
⻚
的更改
作⽤:提⾼更改索引操作性能,涉及更改缓冲区的⼀组功能统称为“更改缓冲区”
,由
“
插⼊缓
,由
“
插⼊缓
冲区”
,
“
删除缓冲区”和 “清除缓冲区
”
组成
,
“
删除缓冲区”和 “清除缓冲区
”
组成
同步策略:当相关索引⻚被带⼊缓冲池⽽相关联的更改仍在更改缓冲区中时,该⻚的更改将
使⽤更改缓冲区中的数据应⽤于缓冲池(
合并
)
中。在系统⼤部分处于空闲状态或 缓慢关机期
合并
)
中。在系统⼤部分处于空闲状态或 缓慢关机期
间运⾏的“清除”操作会定期将新的索引⻚写⼊磁盘
修改上的区别:对于唯⼀索引,所有更新操作要先判断该操作是否违反唯⼀性约束,唯⼀索引不会
⽤change buffer 。若所修改的数据在内存中找到索引对应该存储的位置,判断、到没有冲
突,插⼊值,语句执⾏结束 。找到索引对应该存储的位置,插⼊值,语句执⾏结束。若所修
改的数据不在内存中 ,需要将数据⻚读⼊内存,判断到没有冲突,插⼊值,语句执⾏结束
将更新记录在change buffer
,语句执⾏结束
,语句执⾏结束
结论:唯⼀索引和普通索引在查询性能上没差别,主要考虑对更新性能影响
唯⼀索引可以从数据库上强制去重,但⽤不了change buffer的优化机制,从性能⻆度,推荐
优先考虑⾮唯⼀索引
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
喜欢就支持一下吧





相关推荐

暂无评论内容